Requirements Domain Specifications for Machine-Learned Software Components
Congratulations to S-AISE LAB for winning the NSF grant “NSF: SHF: EAGER: for Transformative Research”.
Machine Learning (ML) algorithms are widely used in building software-intensive systems, including safety-critical ones. Unlike traditional software components, Machine-Learned Components (MLC)s, software components built using ML algorithms, learn their specifications through generalizing the common features they find in a limited set of collected examples. While this inductive nature overcomes the limitations of programming hard-to-specify concepts, the same feature becomes problematic for verifying safety in ML-based software systems. One reason is that, due to MLCs data-driven nature, there is often no set of explicitly written and pre-defined specifications, against which the MLC can be verified.
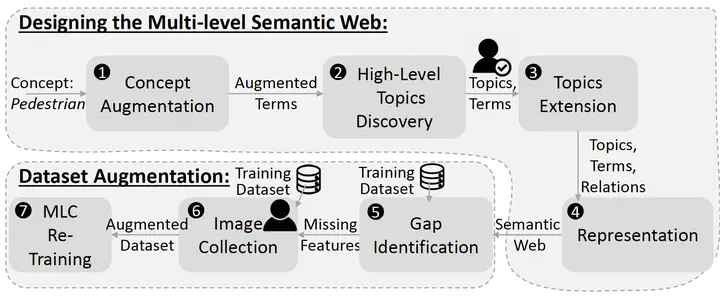
In this regard, we propose to partially specify hard-to-specify domain concepts, which MLCs tend to classify, instead of fully relying on their inductive learning ability from arbitrarily-collected datasets. In this paper, we propose a semi-automated approach to construct a multi-level semantic web to partially outline the hard-to-specify, yet crucial, domain concept pedestrian’’ in automotive domain. We evaluate the applicability of the generated semantic web in two ways: first, with a reference to the web, we augment a pedestrian dataset for a missing feature, wheelchair, to show training a state-of-the-art ML-based object detector on the augmented dataset improves its accuracy in detecting pedestrians; second, we evaluate the coverage of the generated semantic web based on multiple state-of-the-art pedestrian and human datasets.
Hamed Barzamini
PhD Student of Software Engineering for Artificial Intelligence
My research interests include AI-enabled Software Engineering, Big Data Analytic and Explainable AI (XAI).